在GCP Compute Engine架設selenium爬蟲並自動更新到指定Google表單
python selenium這次接到的request跟以往比較不同,之前只有寫過單次執行的爬蟲,但這次的需求是希望除了把資料爬下來之外,可以每週固定更新到指定google表單,所以主管跟同事建議的解法是寫selenium架在Google Cloud Platform Compute Engine VM上、排程每週指定時間自動執行、並使用Google Sheets API把爬下來的資料更新過去。以下會分成三個主要部分敘述:
- Selenium 爬蟲
- Google Sheets API 使用
- GCP Compute Engine VM 架設
1. selenium
雖然這次寫project的重點完全不在爬蟲本身,但因為寫的過程中還是有遇到以前沒解過的問題,這裡做個紀錄。主要新接觸的到的問題有兩個:fake_useragent跟按不到的按鈕。
fake_useragent
如上面提到的,我之前沒有寫過架在雲端自動排程的爬蟲,所以如果遇到會擋爬蟲的網站,都是用最簡單的解法直接加user_agent在request指令的header,但這次情況比較特殊,為了降低程式的失敗機率,我把同事教的fake_useragent拿出來用。
from fake_useragent import UserAgent
寫出的init_driver()function如下。因為執行時不需要瀏覽器跳出來所以用了--headless無頭模式,並用options.add_argument()加入定義好的ua.chrome,這樣程式便可以比較flexible地執行爬蟲了。
def init_driver():
options = webdriver.ChromeOptions()
options.add_argument('--headless')
ua = UserAgent()
options.add_argument("--user-agent=ua.chrome")
driver = webdriver.Chrome(executable_path=ChromeDriverManager().install(),chrome_options=options)
return driver
按不到明明就看得見的按鈕
這次會用速度比較慢的selenium而不直接用python的requests包就是因為我要抓取資料的網頁架構是需要按下數個”more”的按鍵才會return出所有我想抓取的東西。結果努力了半天發現明明已經定位到正確的element,但按鈕怎麼樣就是按不下去。
try:
more_btn = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.XPATH, "xpath_of_your_target_element")))
driver.execute_script("arguments[0].click();", more_btn)
except Exception as e:
print(i, "failed click")
print(e)
pass
觀察網頁原始碼跟error msg後發現,問題可能出在物件被遮蔽。我想做的事情是控制瀏覽器一直往下滾動畫面,然後按下接下來會出現的”more”的按鈕,但因為程式偵測到”more”這個按鈕出現的時候,他其實還沒有出現在可以被觸碰到的地方(聽起來好玄), 因為顯示畫面中他的上層被一個nav bar擋住了,所以我怎麼按都失敗。後來查到的解決方法是用driver.execute_script()執行js指令。
2. Google Sheets API
(1) 申請API憑證
使用Google Sheets API需要credentials,可以直接在GCP申請API憑證。
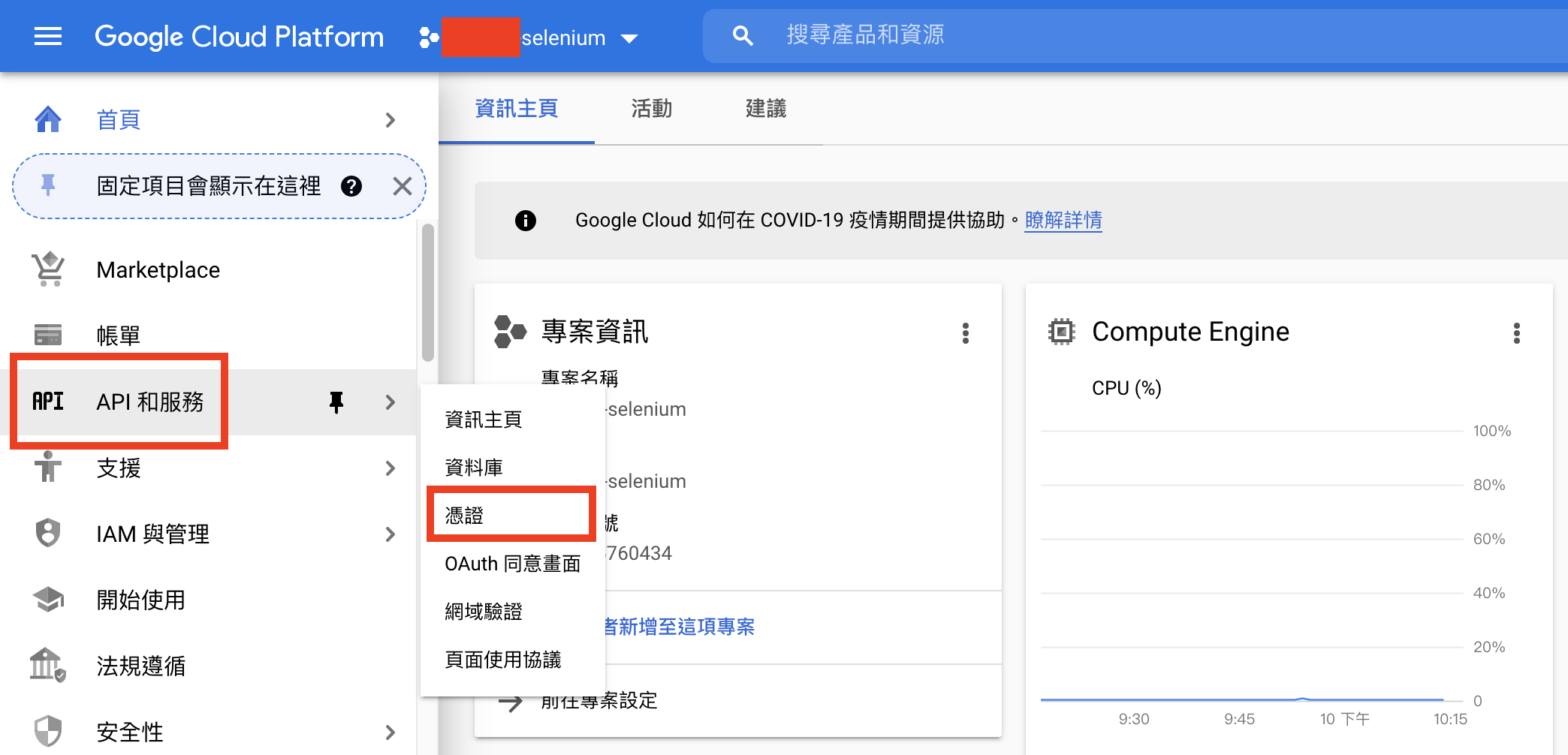
進入「API和服務」頁面之後按上方「建立憑證」>「服務帳戶」
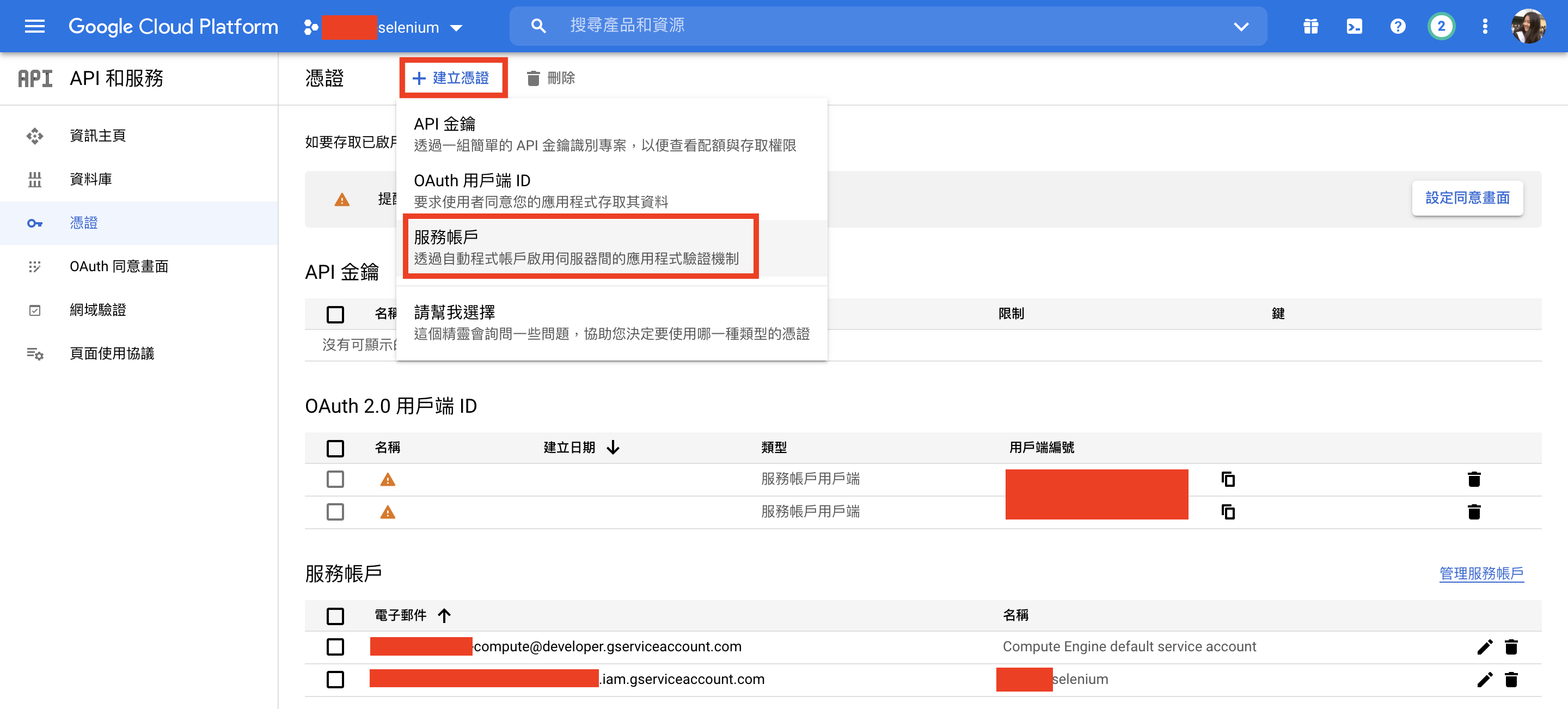
進入「服務帳戶」頁面後把該選的選一選、該填的填一填,選擇建立JSON金鑰。然後你的JSON金鑰就會被下載到local端,把這個檔案放到專案資料夾下面。
(2) 啟用Google Sheets及Google Drive API
「API和服務」 >「資料庫」> 搜尋該API > 按下「啟用」啟用服務。Google Sheets API和Google Drive API步驟相同。
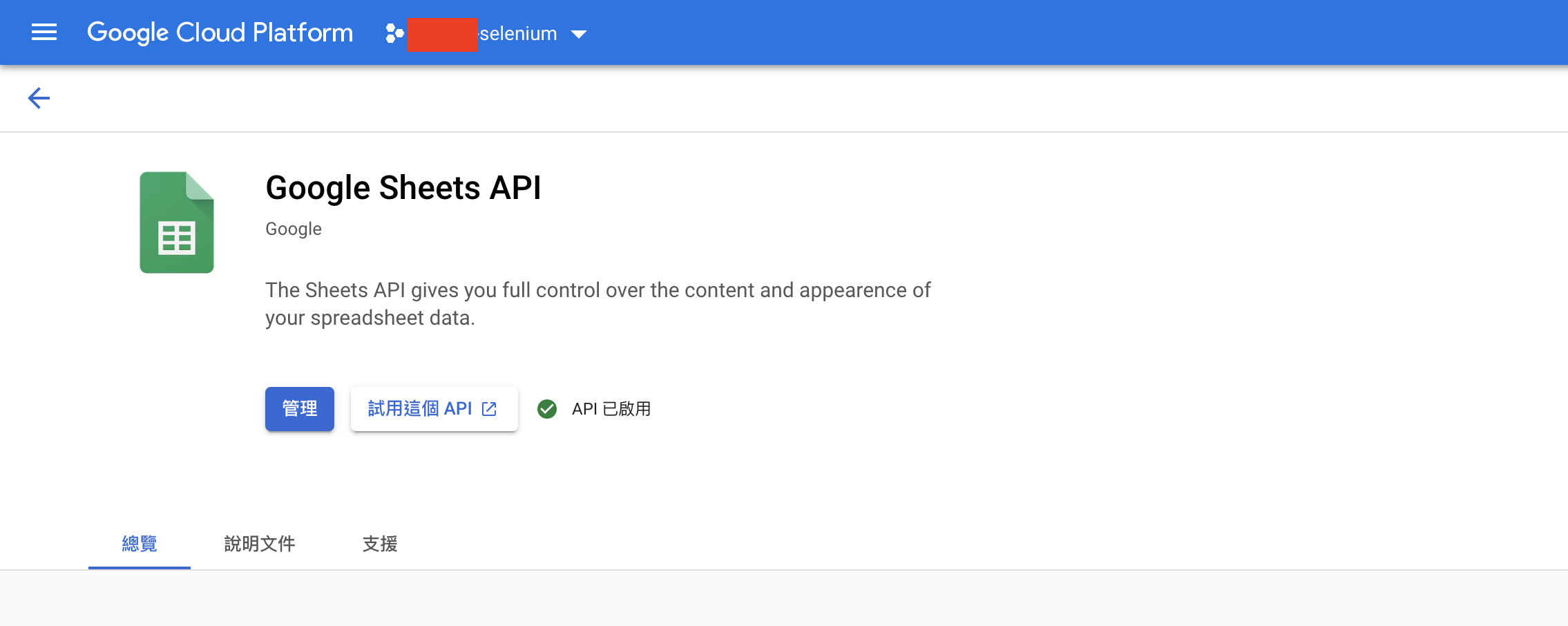
也要記得每個專案如果要使用API的話都要做一樣的動作,否則執行時會出現APIError(因為每個專案開VM都要視為分開的環境)。
(3) 把服務帳戶產生的email address加入成為目標google sheets的編輯者
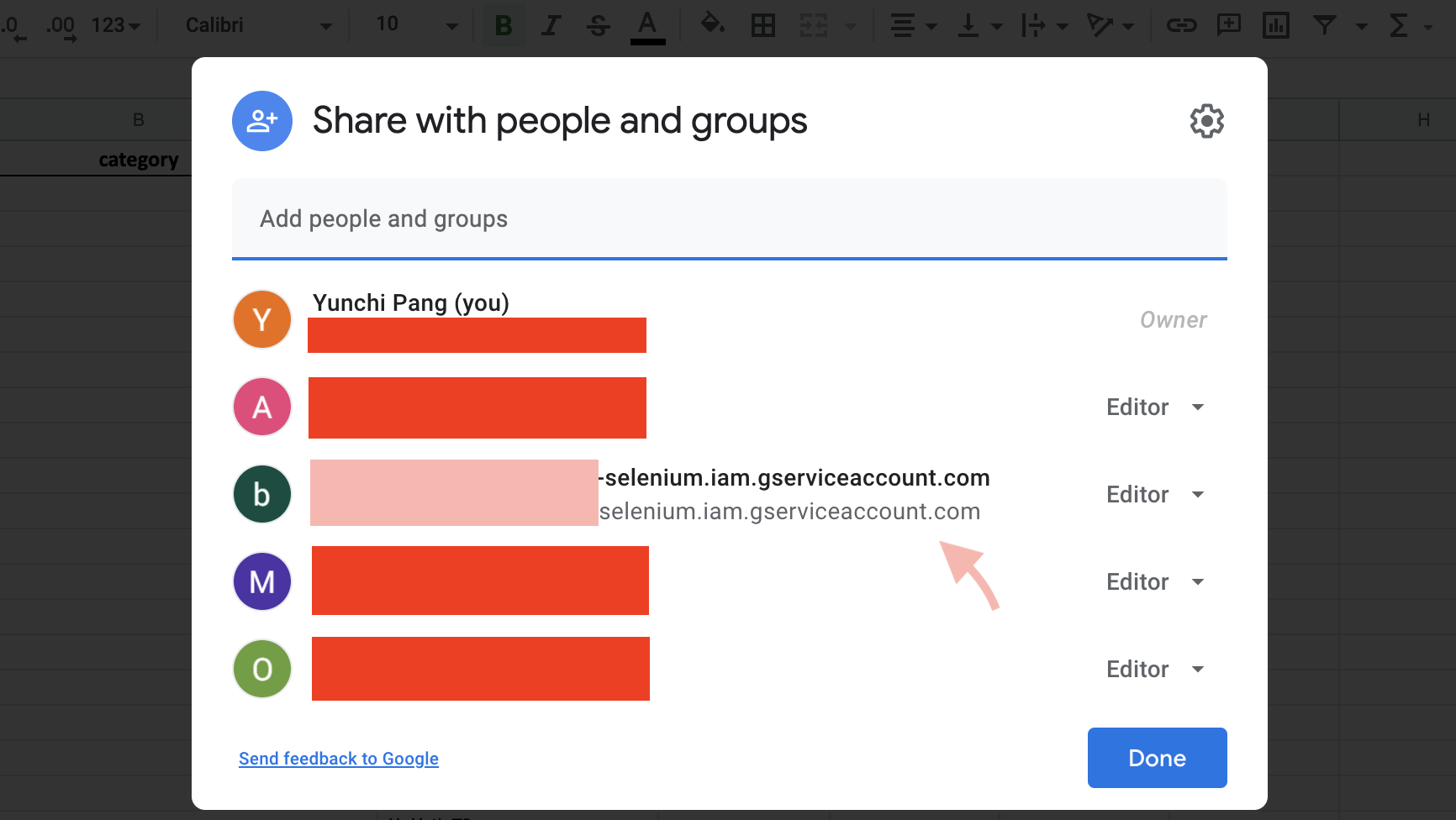
為了讓google sheets可以自動更新,必須把專案的email帳號加入成為目標google sheets的編輯者之一。到時候排程自動執行,便可以看到google sheets上方的紀錄為這支email帳號編輯了此份檔案。
(4) 編輯.py
在python script裡import以下三個配合Google Sheets API使用的python模組。
import gspread
import gspread_dataframe as gd
from oauth2client.service_account import ServiceAccountCredentials
定義scope跟credentials。
scope = ['https://spreadsheets.google.com/feeds', 'https://www.googleapis.com/auth/drive']
# 讀取剛剛從gcp下載下來的憑證
credentials = ServiceAccountCredentials.from_json_keyfile_name("your_credentials.json", scope)
gc = gspread.authorize(credentials)
再來就看各自專案需要什麼api功能了,按照gspread這個模組的語法,可以取得google sheets現有內容、可以清除現有資料、也可以update資料回google sheets。更多寫法可以去查gspread的doc: https://gspread.readthedocs.io/en/latest/
# 取得sheet的access
sheet_obj = gc.open("sheet_title").worksheet("sheet_name")
# 拿sheet裡面的data
data = sheet_obj.get_all_values()
# 做成pandas dataframe
df = pd.DataFrame(data[1:], columns=data[0])
# 清除sheet現有資料
sheet_obj.clear()
# 把df update回google sheets
gd.set_with_dataframe(sheet_obj, df)
3. GCP Compute Engine VM 架設
(1) 新增專案
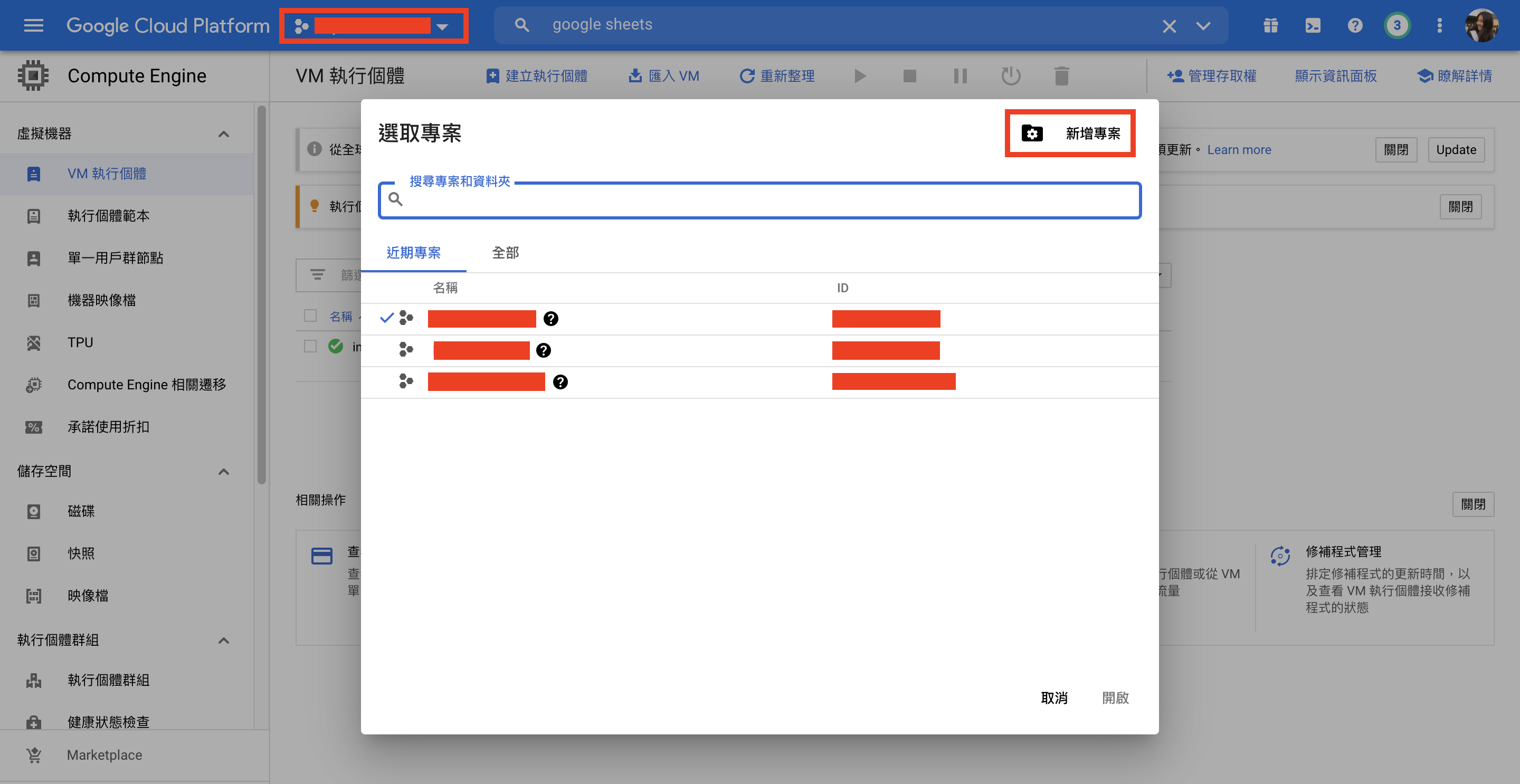
從首頁左上可以點入瀏覽目前所有的project,跳出視窗可以選取現在要進入哪個專案。視窗右上可以「新增專案」。設定完專案名稱和專案ID後便已經成功建立新專案,而這個專案的所有設定之後都可以自行調整(除了專案ID)。
(2) 開虛擬機器
完成建立新專案後,下一步是建立virtual machine。
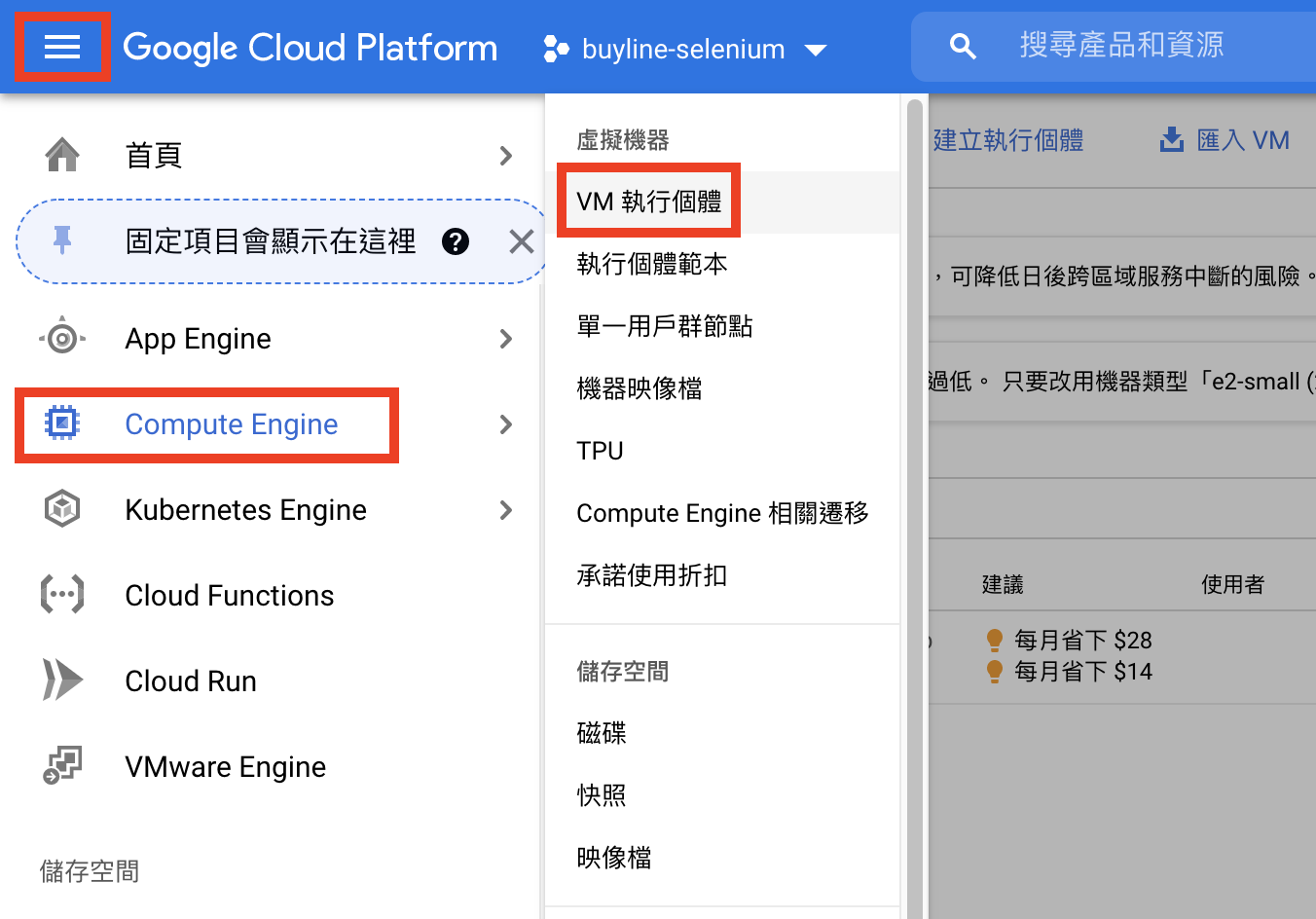
進入頁面點選「建立」VM執行個體之後,等他跑個幾分鐘VM就建立好啦!有很多眼花撩亂的選項可以選,因為我的專案沒什麼特別需求(而且我也不是很懂這麼多機器之間的差別… 繼續努力xd),就都保留default設定。完成建立VM後,便可以看到以下畫面。
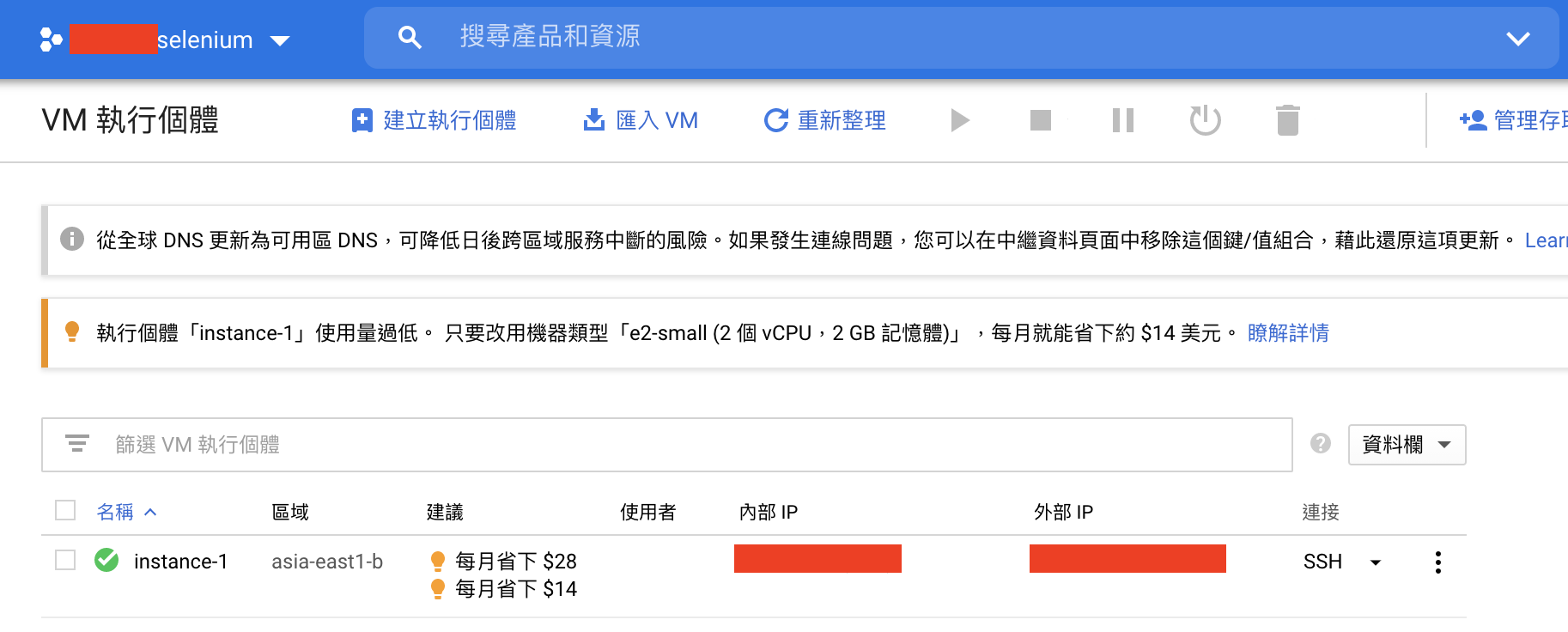
接下來進入SSH終端機畫面,可以開始安裝專案會用到的模組了。要注意前面提到init_driver()裡面有使用到的ChromeDriverManager()在建立機器環境的時候要安裝。另外也要注意,雖然我們平常用pip管理的模組們在local端都有,但在GCP開的機器是全新的另外一個環境,所以script裡面有要用到的module都要再pip3 install安裝喔!
$ sudo apt-get install python3-pip # 安裝pip
$ pip3 install selenium # 安裝selenium
$ sudo apt-get install chromium-driver # 安裝chrome
$ pip3 install webdriver_manager # 安裝Chrome Driver(功能等同原先在local跑selenium的時候需要下載的那支chromedriver.exe)
然後在上傳的.py檔案裡面如下這樣寫的話,selenium就可以順利在GCP環境跑起來了。
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(executable_path=ChromeDriverManager().install())
(3) 上傳python script以及API憑證
一樣停留在終端機畫面,按下右上角的settings > 上傳檔案,選擇要在VM上面跑的python script,也要記得上傳之前在建立API憑證部分取得的json credentials。
(4) crontab排程執行
是否要排程自動執行就看這份專案是否有需求了。以我的專案為例,提出需求的部門希望每週更新,所以我就使用linux內建crontab排程為每週一下午兩點會自動執行我上傳的.py文件。範例如下:
0 14 * * 1 /usr/bin/python3 /home/username/name_of_the_script.py
排程執行需要注意的是,vm的時區、crontab的時區、還有專案希望存在的時區可能不同。一開始我的機器跟crontab時區都是+0,但第一次排程因為時區錯誤而失敗,我就把機器時區調到我所在的台北+8,但crontab依舊排程0 14 * * 1還是沒有在對的時間執行,因此發現crontab的時區也是需要調整的。最後覺得方便的方法是把crontab排程的時間-8,改為0 6 * * 1,便可以順利執行了。如果想要檢查過去crontab的執行紀錄可以使用以下指令:
grep CRON /var/log/syslog
另外,如果跟我一樣想改機器時區,可使用以下指令。跳出GUI之後就可以直接使用上下左右鍵選取自己要調整過去的時區了。
sudo -s
dpkg-reconfigure tzdata
下一篇會接著寫同一份專案如果不想花錢花時間架到雲端運算,可以簡單一點打包成執行檔,一樣可以在其他同事的電腦環境裡運行,不受限於是否有安裝python3及其他模組。
跪謝主管、同事、前輩指點及網路資源:
【爬蟲筆記】如何在 GoogleComputeEngine 上運行 selenium 爬蟲