使用groupon產品評價做簡易文字雲及情感分析
python NLP接續上一篇我們用selenium爬到了groupon網站上特定產品頁的所有評價,今天要做的就是後續的文字雲及情感分析。大部分都會與這篇相似(畢竟是同份作業)但因為資料量差很多(8-10筆&1000多筆),我還是希望可以跑出來看看結果有何不同。
開始寫分析之前,先把手上從groupon爬下來的資料讀進來,取名叫做comments。
f = open('all_comments.txt', 'r').readlines()
comments = [i.strip('\n') for i in f]
len(comments) # returns 1002
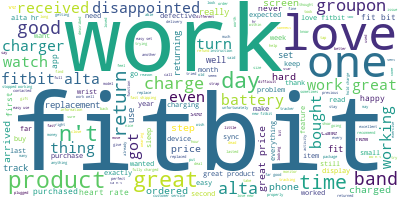
1. Please write down the word (or words) with the highest frequency in the product reviews for the product.
import nltk
import string
from matplotlib import pyplot as plt
%matplotlib inline
from wordcloud import WordCloud, STOPWORDS
def clean_text(x):
sentences = sum([nltk.sent_tokenize(c) for c in x], [])
words = [nltk.tokenize.word_tokenize(s.lower()) for s in sentences]
words = sum(words, [])
words = [w for w in words if w not in string.punctuation]
words = [w for w in words if w not in nltk.corpus.stopwords.words('english')]
lemmatizer = nltk.stem.wordnet.WordNetLemmatizer()
l_words = [lemmatizer.lemmatize(i) for i in words]
return l_words
words = clean_text(all_comments_flat)
paragraph = " ".join(w for w in words)
stopwords = set(STOPWORDS)
wordcloud1 = WordCloud(stopwords=stopwords, background_color="white").generate(paragraph)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud1, interpolation='bilinear')
plt.axis('off')
plt.title("product")
plt.show()
這題要找出現頻率最高的字,教授教的方法是用文字雲來解。首先我們將爬下來的文字都處理好(包含將整個comment解成sentences、將sentences解成words、移除意義不大的stopwords、移除標點符號、lemmatization等動作)再將全部的words組成一個paragraph,就可以用WordCloud製造出一張文字雲圖片。很明顯地這回合勝出的是”fitbit”。
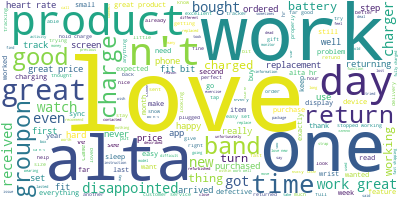
2. We find that the result is not satisfying. We want to get rid of the word with the highest frequency. Please remove it from the word cloud. Now what is/are the word(s) with the highest frequency for the product?
stopwords.update(['fitbit']) # add "fitbit" to stopwords
wordcloud2 = WordCloud(stopwords=stopwords, background_color="white").generate(paragraph)
plt.figure(figsize=(10, 10))
plt.imshow(wordcloud2, interpolation='bilinear')
plt.axis('off')
plt.title("product")
plt.show()
但是這樣不對啊?”fitbit”是跟產品本身名稱相關的詞彙,跟消費者的評價沒有什麼關係,所以我們必須移除”fitbit”這個字,再解讀一次文字雲。這裡的用法是把”fitbit”這個字手動加到stopwords裡面,使文字雲裡面不會再出現該字。再看一次文字雲,出現最頻繁的字變成”love”了!
3. Based on the definition we used it class, what is the ratio of the satisfactory comments to the total number of comments for the product?
p = open('positive.txt','r').readlines()
positive = [i.strip('\n') for i in p]
n = open('negative.txt','r').readlines()
negative = [i.strip('\n') for i in n]
import pandas as pd
df = pd.DataFrame(comments, columns=['comment'])
# define a new function cleaning single comment
def clean_comment(x):
words = nltk.tokenize.word_tokenize(x.lower())
words = [w for w in words if w not in string.punctuation]
words = [w for w in words if w not in nltk.corpus.stopwords.words('english')]
lemmatizer = nltk.stem.wordnet.WordNetLemmatizer()
l_words = [lemmatizer.lemmatize(i) for i in words]
return words
df['comment_clean'] = df['comment'].apply(lambda x: clean_comment(x))
def get_sentiment1(x):
p = 0
n = 0
for w in x:
if w in positive:
p += 1
elif w in negative:
n += 1
if p > n:
return 'positive'
elif p == n:
return 'neutral'
else:
return 'negative'
df['sentiment1'] = df['comment_clean'].apply(lambda x: get_sentiment1(x))
這題要求用課內定義的計算方式算出顧客對於這項產品的滿意程度(satisfactory ratio),解法一樣是利用手上清理好的text去跟positive和negative詞包裡面的字作配對,進一步算出這些comments是正面還是負面的評論。接著定義get_sentiment()這個function,如果該詞存在於positive詞包裡面,就在他p的分數上+1,反之如果該詞存在於negative的詞包裡面,在他的n分數上+1,最後比較p跟n誰比較大,如果平手就return中性。結果得到0.63左右的分數。
def get_satisfactory_ratio(x):
return len(x[x=='positive'])/len(x)
sr1 = get_satisfactory_ratio(df['sentiment1'])
sr1 # 0.6346534653465347
4. If we want to redefine “neutral” sentiment, and make the case when the number of positive words equals the number of negative words as “negative”, what would be satisfactory ratio for the product?
def get_sentiment2(x):
p = 0
n = 0
for w in x:
if w in positive:
p += 1
elif w in negative:
n += 1
if p > n:
return 'positive'
else:
return 'negative'
df['sentiment2'] = df['comment_clean'].apply(lambda x: get_sentiment2(x))
sr2 = get_satisfactory_ratio(df['sentiment2'])
sr2 # 0.6346534653465347
最後一題要求轉換定義中性情感的方式,如果comment裡面正面和負面的詞彙數量一樣多,則定義該則comment為negative,但其實這樣算出來的satisfactory ratio還是相同的,畢竟是用positive/all的比例來算。教授出的題組大約是這樣,祝大家也祝自己期末考順利(突然開始問好?)